
Hi again,
As we already installed and configured Debian Linux we are fully set and ready to install Cassandra cluster for collecting out VM metrics from vCloud Director 8.11 and 8.20.
As we could read in VMware blog it is quite usefull. and design should look like this: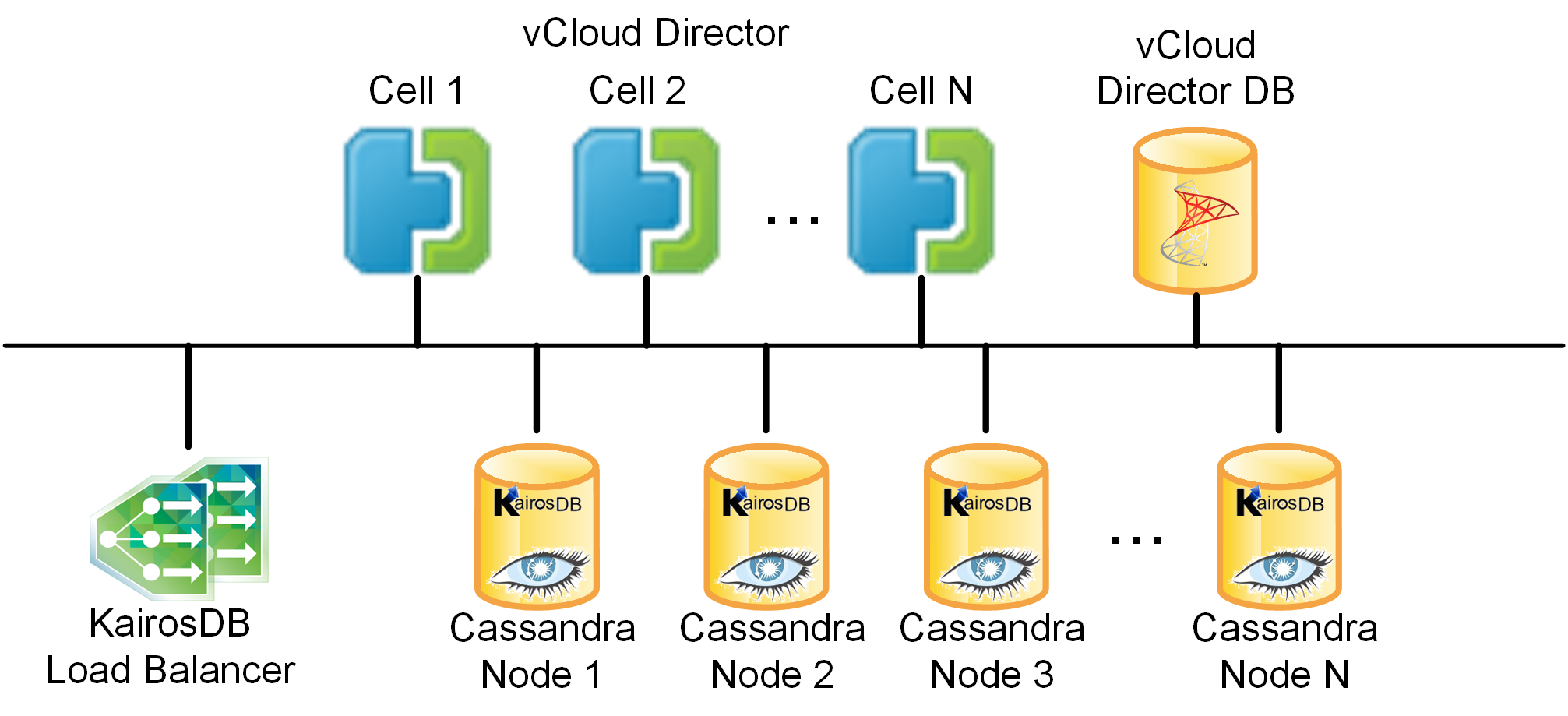
But in my plans we will implement separately KairosDB and Cassandra VMs.
- Minimum cluster size is three nodes (must be equal or larger than the replication factor). Use scale out rather than scale up approach because Cassandra performance scales linearly with number of nodes.
- Estimate I/O requirements based on the expected number of VMs, and correctly size the Cassandra cluster and its storage.
n … expected number of VMs
m … number of metrics per VM (currently 8)
t … retention (days)
r … replication factor
Write I/O per second = n × m × r / 10
Storage = n × m × t × r × 114 kB
For 30,000 VMs, the I/O estimate is 72,000 write IOPS and 3288 GB of storage (worst-case scenario if data retention is 6 weeks and replication factor is 3).
Cassandra structure after installation is the following:
| Configuration Files | Locations |
|---|---|
| cassandra.yaml | /etc/cassandra |
| cassandra-topology.properties | /etc/cassandra |
| cassandra-rackdc.properties | /etc/cassandra |
| cassandra-env.sh | /etc/cassandra |
| cassandra.in.sh | /usr/share/cassandra |
The packaged releases install into these directories:
| Directories | Description |
|---|---|
| /var/lib/cassandra | Data directories |
| /var/log/cassandra | Log directory |
| /var/run/cassandra | Runtime files |
| /usr/share/cassandra | Environment settings |
| /usr/share/cassandra/lib | JAR files |
| /usr/bin | Binary files |
| /usr/sbin | |
| /etc/cassandra | Configuration files |
| /etc/init.d | Service startup script |
| /etc/security/limits.d | Cassandra user limits |
Lets start installing Cassandra 3.0 , KairosDB and prerequisites for it!
We need to install Java 8 for Cassandra 3.0 and KairosDB first:
- We need to create repository list for java:

- Add the following repos to the list

- “apt-get update” – to update the repositories
- “apt-get install oracle-java8-installer -y” wait for installation to start installation. accept the licenses.
- After installation we shall check the Java version by running “Java -version” and get result

After Java installation we can install Cassandra:
- We need to create repository list for cassandra and add repositories in it:
touch /etc/apt/sources.list.d/cassandra.sources.list
echo "deb https://www.debian.datastax.com/community stable main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
echo "deb https://www.debian.datastax.com/community stable main" | tee -a /etc/a pt/sources.list.d/cassandra.sources.list - apt-get update – to update repositories
- apt-get install dsc30 – to install cassandra
- systemctl status cassandra

- systemctl stop cassandra – to stop the service
As we want to keep our database correctly we have to mount separate hdd to /var/lib/cassandra folder (as all the data located there):
- fdisk -l – to see all of the volumes install and search for /dev/sdb (c…)
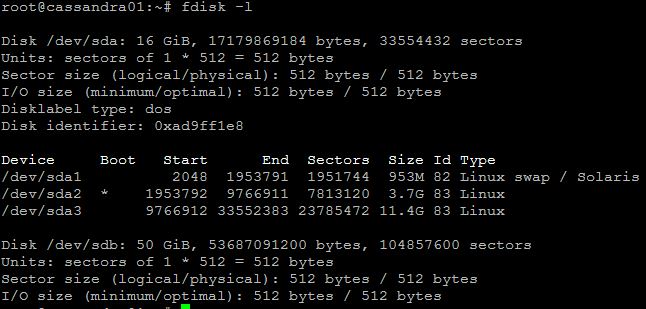
- Now as we are sure that our device is called sdb and correct size shall run the following commands:
fdisk /dev/sdb
Command (m for help): o
Command (m for help): n
Select (default p): p
Partition number (1–4, default 1): 1
Command (m for help): w
mkfs.ext4 /dev/sdb1 - Now we have to map this disk to our lib folder for cassandra (as all of the data located there) we will use rsynch and fstab:
mkdir /mnt/cassandra
mount /dev/sdb1 /mnt/cassandra/
cp -ax /cassandra /mnt/cassandra/
mv cassandra/ cassandra.old
mkdir cassandra
umount /dev/sdb1
mount /dev/sdb1 cassandra
chown cassandra:cassandra cassandra
vim /etc/fstabAnd add following line to the list:
/dev/sdb1 /var/lib/cassandra ext4 defaults 0 1
As now we are done with preparing one cassandra node we can proceed and clone it to another 2 (as you remember minimal requirement is 3 nodes).
- To achieve this goal we need to run simple command in VMware powerCLI:
New–VM -name Cassandra03.demo.lab –VM $cassa –ResourcePool $RP
- Don’t forget to change hostnames and IP address in:
vim /etc/hosts
vim /etc/hostname
vim /etc/network/interfaces
vim /etc/ssh/sshd_config
Now the time has come for configuring cassandra itself:
- Make sure that your nodes are not running by entering the command:
systemctl status cassandra
systemctl stop cassandra - As we cloned our VMs we will have token conflicts inside of cluster so remove all the data by following commands:
rm -rf /var/lib/cassandra/commitlog/*
rm -rf /var/lib/cassandra/data/*
rm -rf /var/lib/cassandra/saved_caches/* - Edit /etc/cassandra/cassandra.yaml
cluster_name: ‘VM_Metrics’
num_tokens: 256
seed_provider:
– class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
– seeds: "10.1.253.115,10.1.253.116,10.1.253.117"
listen_address: 10.1.253.115
start_rpc: true
rpc_address: 0.0.0.0
rpc_port: 9160
broadcast_rpc_address: 10.1.253.115
endpoint_snitch: GossipingPropertyFileSnitch
auto_bootstrap: false - Edit /etc/cassandra/cassandra-rackdc.properties
dc=DataCenter01
rack=Rack01 - Edit /etc/cassandra/cassandra-topology.properties
10.1.253.15:DataCenter01:Rack01
10.1.253.16:DataCenter01:Rack01
10.1.253.17:DataCenter01:Rack01 - Do the same on other nodes (don’t forget to change the IP-addresses where required)
- After it we shall start cassandra service on nodes (one by one):
systemctl start cassandra
- You shall see the following picture when run the command:
nodetool status

Our Cassandra cluster is ready to recieve data from KairosDB which we gonna install now:
- Prepare Linux VM (as base system we use Debian – installation, configuration)
- Download and unpack KairosDB
wget https://github.com/kairosdb/kairosdb/releases/download/v1.1.3/kairosdb-1.1.3-1.tar.gz –no-check-certificate
tar -xzf kairosdb-1.1.3-1.tar.gz - Attach additional vHDD and mount it (same as we did with cassandra)
mkdir /var/lib/kairosdb
mount /dev/sdb1 /var/lib/kairosdb/
mv kairosdb/* /var/lib/kairosdb/
vim /etc/fstabAdd the following:
/dev/sdb1 /var/lib/kairosdb ext4 defaults 0 1 - Edit /var/lib/kairosdb/conf/kairosdb.properties
kairosdb.jetty.address=10.1.253.118
# kairosdb.service.datastore=org.kairosdb.datastore.h2.H2Module
kairosdb.datastore.concurrentQueryThreads=5
kairosdb.service.datastore=org.kairosdb.datastore.cassandra.CassandraModule
kairosdb.datastore.cassandra.host_list=10.110.1.253.115:9160,10.253.116:9160,10.1.253.117:9160
kairosdb.datastore.cassandra.keyspace=kairosdb - Need first run KairosDB:
/var/lib/kairosdb/bin/kairosdb.sh run
You will see the following picture:

- Now we have to start KairosDB in the background:
/var/lib/kairosdb/bin/kairosdb.sh start
As a result we will see the following picture in our browser (dont forget default port is 8080)
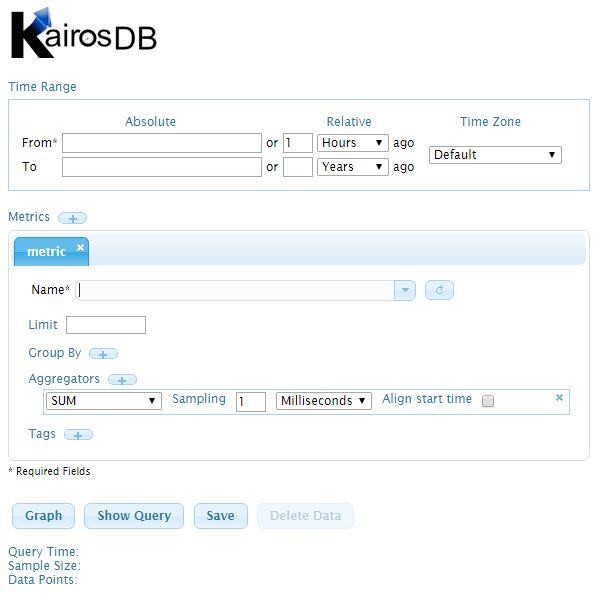
Now we are on final step we have to show vCloud Director where to store data.
- First we have to disable
service vmware-vcd stop
cd /opt/vmware/vcloud-director/bin/
./cell-management-tool configure-metrics –repository-host 10.1.253.118 –repository-port 8080
service vmware-vcd start ;tail -f /opt/vmware/vcloud-director/logs/cell.log - After this is done give sometime for data to be collected and you can check metrics in KairosDB page.
Thank you for reading.
Leave a Reply